
How to Improve Your RFP Process Using Salesforce + AI: A Practical Guide
See how AI can improve your RFP Process with AI in Salesforce





See how AI can improve your RFP Process with AI in Salesforce

See how AI can improve your Email 2 Case in Salesforce

See how AI can create Knowledge Articles from Cases Solved in Salesforce

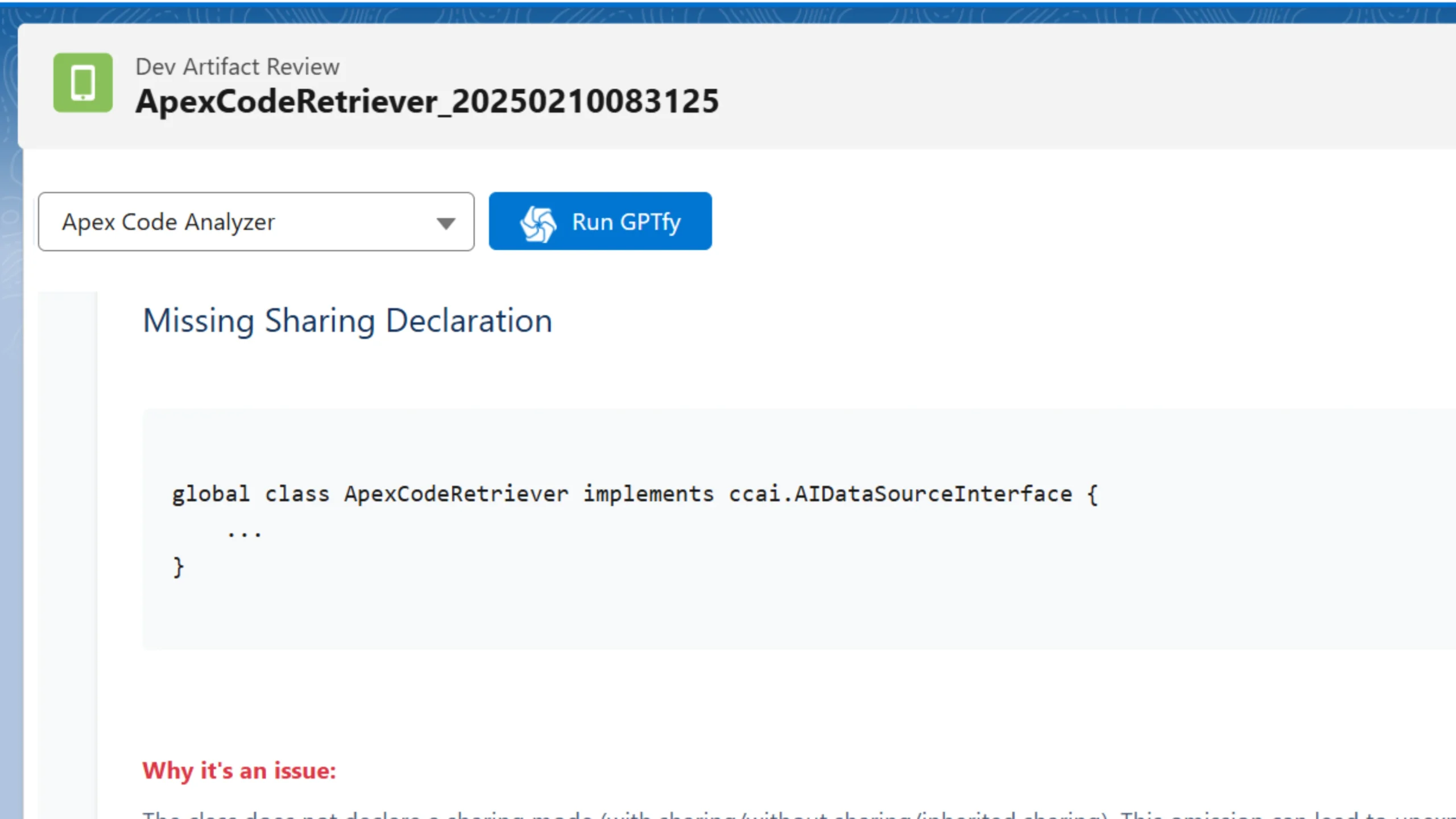
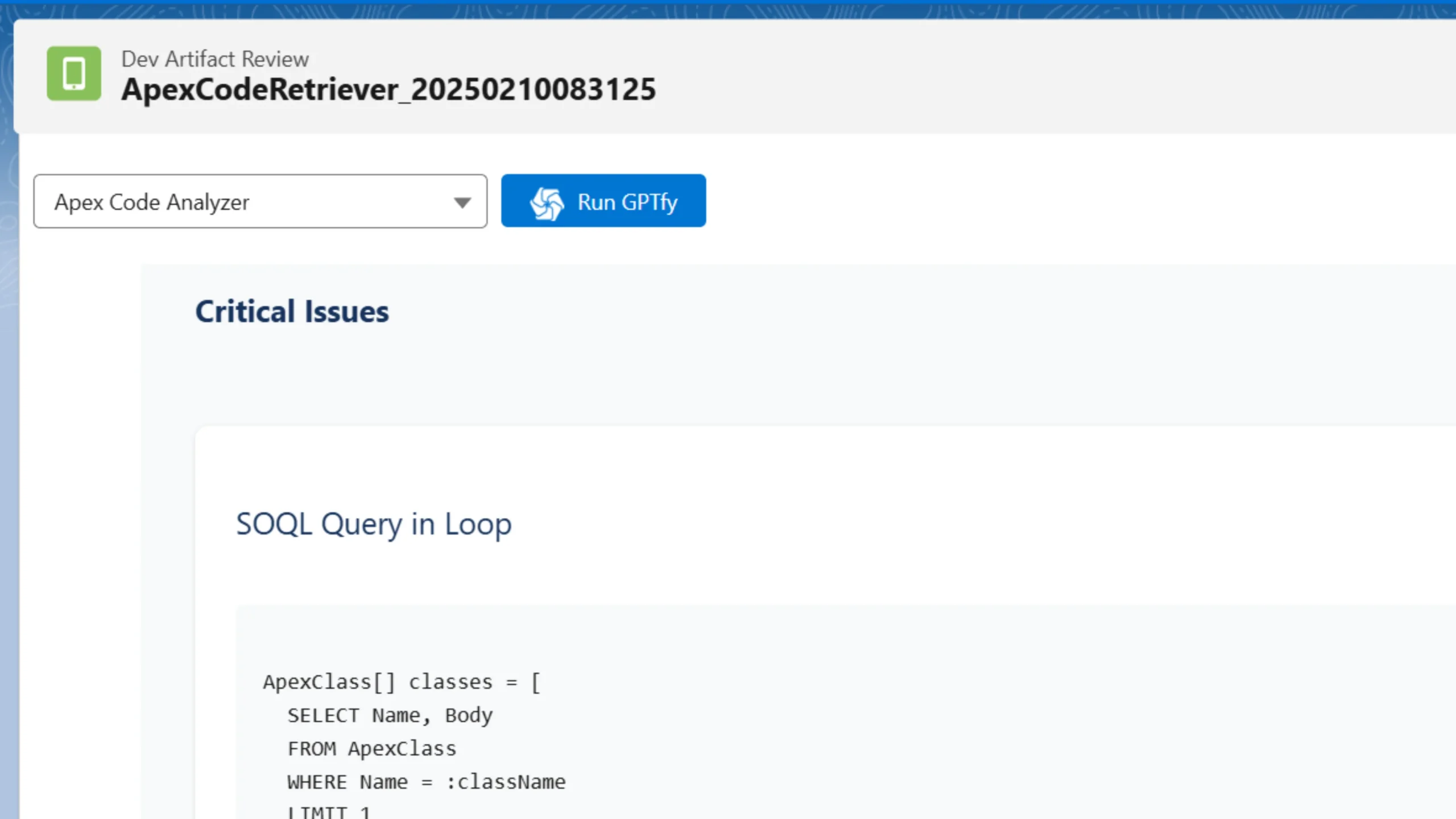
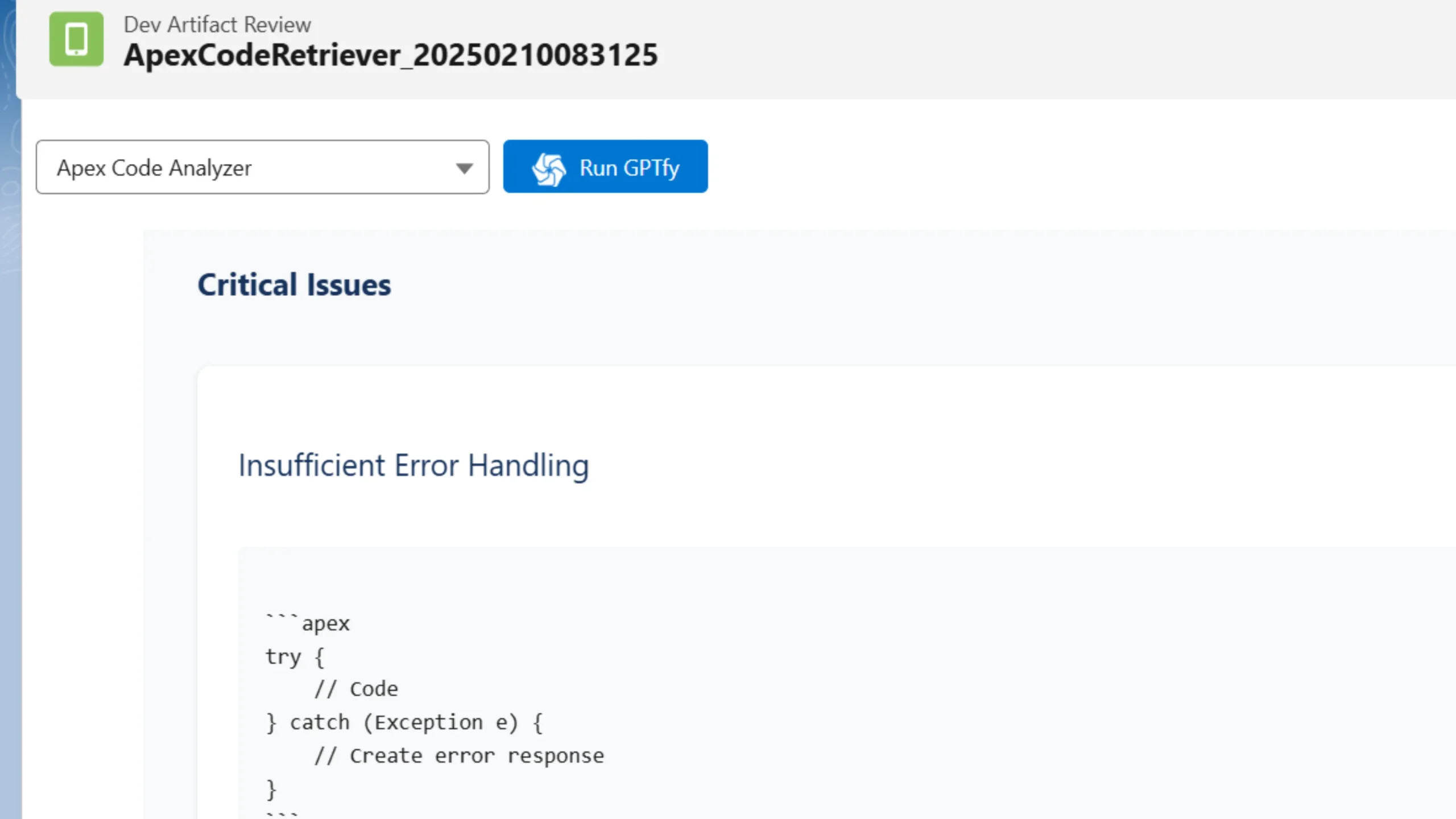
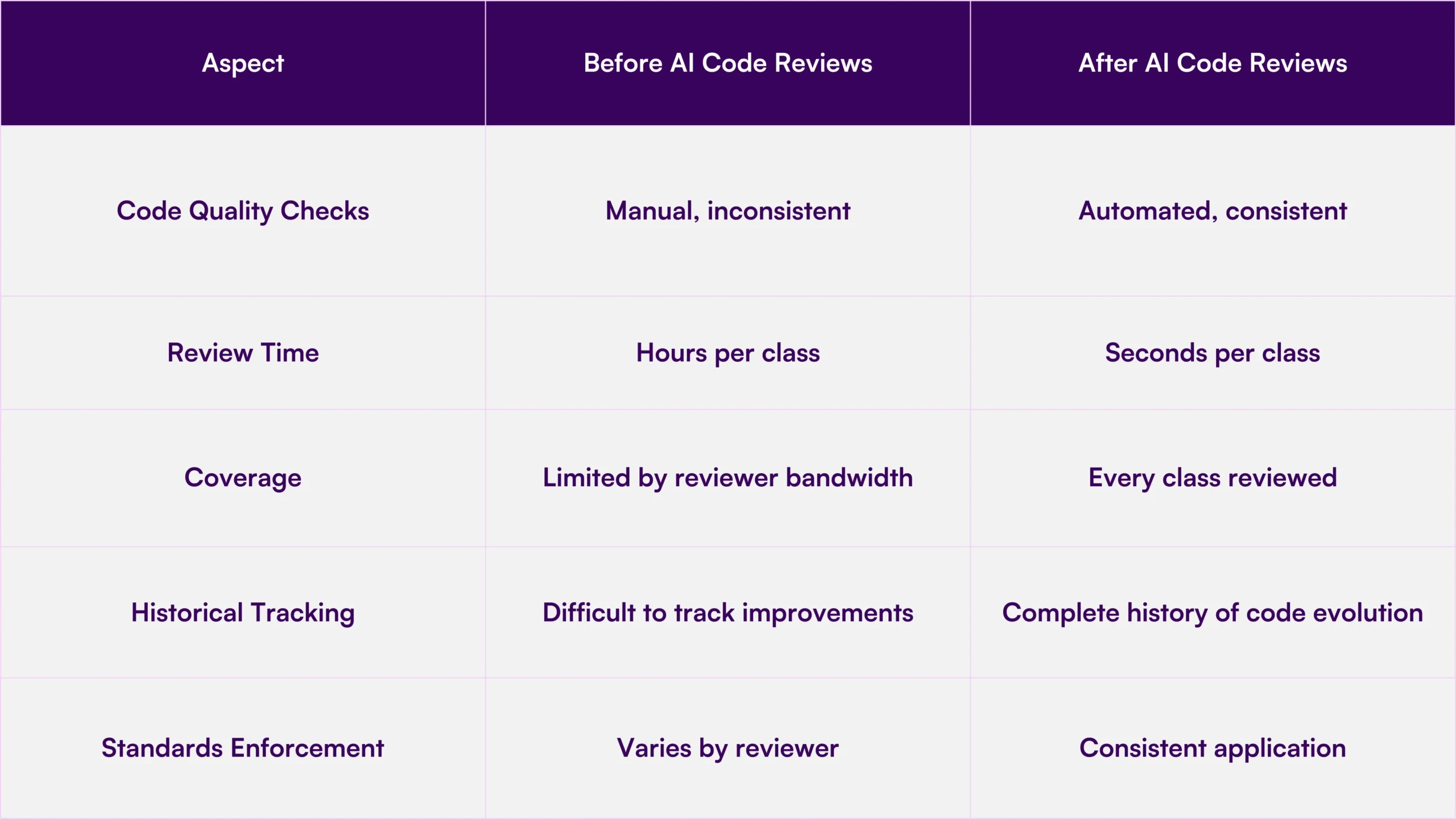
Learn how AI can do Apex Code Reviews in Salesforce

Learn how AI can do Apex Code Reviews in Salesforce

Learn how AI can give you competitive insights inside Salesforce with GPTfy.

Understand the key factors that can impact your Salesforce AI project

Move from AI planning to real-world implementation in your Salesforce environment

Guide to implement AI securely in your Salesforce

Find out how you can improve your business with AI in Salesforce.

Find out what AI model makes sense for your Salesforce?

Connect Llama, Meta’s Open-source AI model, to your Salesforce with GPTfy