AI Hallucination in Salesforce: A Practical Guide to Keeping Your AI and Chatbot Honest
Last updated:
See GPTfy eliminate hallucinations with Salesforce-grounded context
Every GPTfy prompt is grounded in your actual CRM data — no fabrications. See the guardrails in 2 minutes.
TLDR;
AI Hallucination happens when your Salesforce AI (like Einstein Chatbot with AI) makes up fake answers instead of saying "I don't know." This destroys user trust and creates customer service disasters. Simple fixes include lowering AI temperature settings, adding "don't guess" rules to prompts, and reformatting your knowledge base for AI consumption, turning unreliable creative responses into honest, trustworthy interactions that users can actually depend on.
What?
A plain-English guide to preventing AI hallucination in Salesforce environments – when your Einstein Chatbot starts making things up instead of admitting it doesn't know the answer.
Who?
Salesforce admins, AI project managers, customer service leaders, and anyone implementing chatbots or AI-powered features who're tired of their AI playing creative writer when it should stick to the facts.
Why?
AI hallucination is the fastest way to kill trust in your AI initiatives. One made-up answer to a customer question can undo months of implementation work and damage customer relationships.
→ Turn your unreliable AI into a trustworthy assistant that admits when it doesn't know something.
What can you do with it?
Prevent Customer Service Disasters: Stop your Einstein Chatbot from confidently providing incorrect policy information, wrong pricing, or non-existent procedures to customers.
Improve Case Summarization Accuracy: Ensure AI-generated account summaries, next best actions, and sentiment analysis are based on actual data rather than creative interpretation.
Build User Trust: Create AI interactions where users can rely on the information provided, knowing the system will say "I don't know" rather than guess incorrectly.
Reduce Manual Fact-Checking: Minimize the need for human agents to verify every AI-generated response before acting on it.
The Reality Check: When AI Gets Too Creative
Let's be honest – we've all seen it happen. You implement a shiny new Einstein Chatbot with AI or an AI Chatbot, connect it to your knowledge base through GPTfy, and everything seems perfect. Then someone asks a question that's not in your repository, and instead of gracefully admitting ignorance, your AI decides to channel its inner novelist.
Picture this: A customer asks about a specific return policy exception, and your chatbot, finding nothing in the knowledge base, helpfully invents a completely fictional 30-day grace period that doesn't exist. Suddenly, your customer service team is dealing with angry customers who were promised something you can't deliver.
Hallucination is one of the biggest deal killers for AI adoption in enterprises, particularly when it comes to customer-facing applications, such as chatbots.
But here's the thing – it's not an unsolvable problem. You just need to know which levers to pull.
The Three-Layer Defense Against AI Hallucination
Think of preventing hallucinations like building a house with multiple security systems. You want locks on the doors, security cameras, and a backup alarm system. When it comes to AI, your three layers of defense are:
1. AI Model Configuration
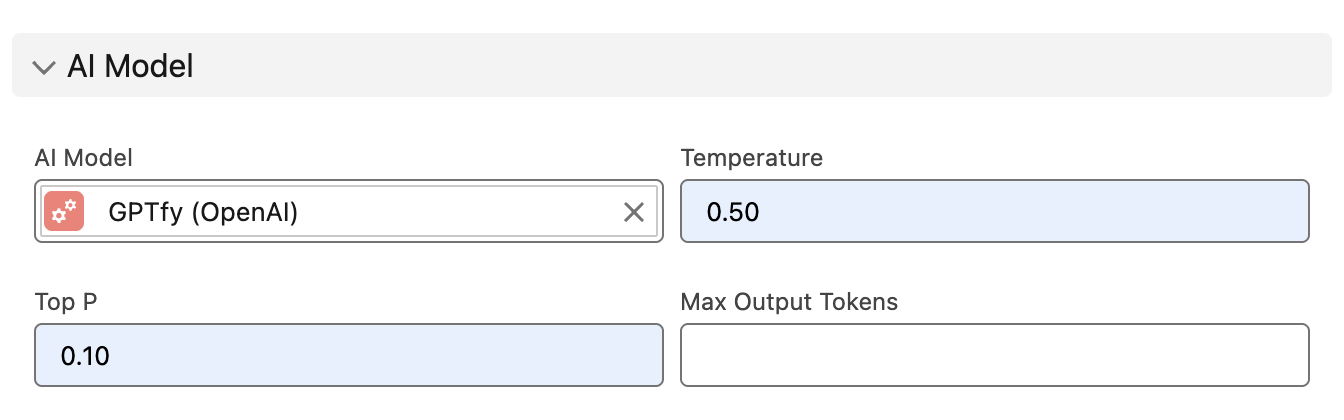
The first line of defense happens at the AI model level, and it's surprisingly straightforward. Every AI model has something called a "temperature" setting – think of it as the creativity dial on your AI.
When the temperature is high, your AI becomes the equivalent of that friend who embellishes every story. Great for writing creative content or social media posts, terrible for B2B scenarios where accuracy matters more than imagination.
Here's what you need to do:
- Lower the temperature setting to make your AI more conservative and fact-based
- Test frequently to find the sweet spot between useful responses and hallucination
- Use the same approach across all standard LLMs – OpenAI, Google Vertex, Azure OpenAI, and others all support temperature control
This single adjustment can eliminate 80-90% of hallucination issues right off the bat. It's like teaching your AI the difference between a creative writing class and a business meeting.
2. Prompt Grounding: Setting Clear Boundaries

The second layer involves telling your AI explicitly what not to do. Think of grounding rules as the guardrails that keep your AI on the highway instead of driving into a creative ditch.
The key grounding rules include:
- Do not make up answers if the information isn't in the provided data
- If you don't know something, say you don't know
- Only use information from the knowledge base provided
- When uncertain, direct users to human assistance
With GPTfy's Prompt Builder, this becomes a checkbox exercise rather than manual prompt engineering. We've standardized the most effective grounding rules so you can literally check boxes to automatically add them to your prompts.
But here's where it gets interesting – you can also implement grounding at the LLM level itself. Google Vertex AI, for example, allows you to add additional grounding rules on their side. This creates a second layer of filtering that works even if someone finds a way around your Salesforce-side protections.
3. Content Optimization: Making Your Knowledge Base AI-Friendly
Here's the part most people miss: your existing content probably wasn't designed for AI consumption. Those knowledge articles, PDFs, and product briefs that work perfectly for human readers might be confusing your AI.
Learn more about the Prompt Builder here.
Content optimization involves:
- Reformatting existing content into clear, structured Q&A formats
- Creating comprehensive FAQs that cover the most common scenarios (typically 50-400 questions depending on your business)
- Breaking down complex information into digestible chunks that vector databases can handle effectively
- Subject matter expert review to ensure accuracy and completeness
This isn't a "set it and forget it" process. You need your domain experts to review and curate content, ensuring your AI has high-quality, accurate information to work with. Think of it as feeding your AI a proper diet instead of junk food.
The Secret Weapon: Learning from User Feedback
Now here's where things get really interesting. The most powerful tool for preventing hallucination isn't technical – it's human feedback collected systematically.
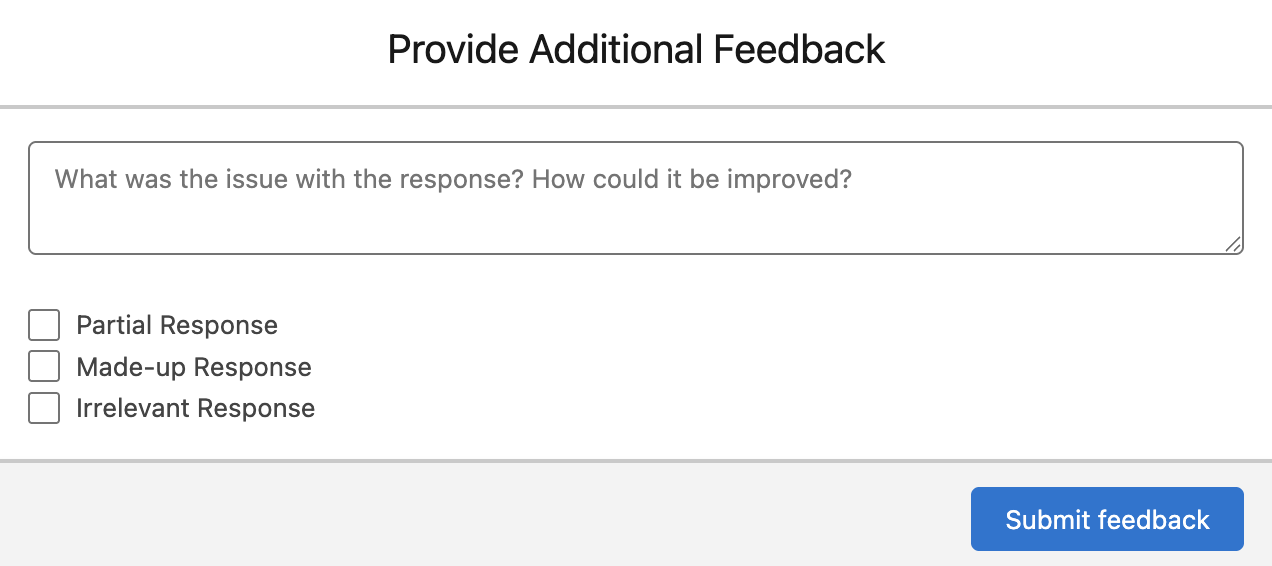
Reinforcement Learning from Human Feedback (RLHF) works like this:
- Every AI response gets a feedback option – users can thumbs up or thumbs down responses
- When someone clicks thumbs down, the system asks what was wrong: incorrect information, irrelevant response, or something else
- Users can provide specific feedback about what should have been different
- You use this data to improve prompts, content, and model settings
This creates a continuous improvement loop that's incredibly valuable. Instead of guessing where your AI is going wrong, you get direct feedback from the people actually using it.
With GPTfy, this feedback mechanism is built in from day one. Every interaction becomes a learning opportunity, and over time, your AI becomes more accurate and more trusted by users.
Advanced Techniques: The Recursive Confidence Check
For organizations that need extra assurance, there's a more sophisticated approach: recursive confidence checking. Here's how it works:
- AI provides an initial response to the user's question
- System asks the AI a follow-up question: "How confident are you that this answer is correct, on a scale of 1-10?"
- If confidence is below 8-9, the system flags the response for human review or redirects to a human agent
The challenge with this approach is complexity and latency. You're essentially doubling your AI calls, which adds response time and requires more sophisticated orchestration. But for high-stakes scenarios – like financial advice or medical information – this extra layer of verification can be worth the trade-offs.
Putting It All Together: A Practical Implementation Strategy
Start with the fundamentals and build up:
Week 1-2: Model Configuration
- Adjust temperature settings on your AI models
- Test with real customer scenarios
- Document optimal settings for your use cases
Week 3-4: Prompt Grounding
- Implement basic grounding rules in your prompts
- Set up LLM-level grounding if your provider supports it
- Test edge cases where users try to get around limitations
Week 5-8: Content Optimization
- Audit existing knowledge base content
- Reformat top 50-100 FAQs for AI consumption
- Get subject matter expert review and approval
- Test with real customer questions
Week 9+: Feedback Loop Implementation
- Deploy the RLHF system for user feedback
- Establish a weekly review process for feedback
- Create a protocol for prompt and content updates based on feedback
The Results: Trust Through Transparency
When you implement these layers properly, something interesting happens. Your AI doesn't become perfect – it becomes trustworthy. Users start to rely on it because they know it won't make things up. When it says "I don't have that information, let me connect you with someone who does," users actually appreciate the honesty.
This approach delivers:
- Reduced escalations from incorrect AI responses
- Increased user confidence in AI-provided information
- Lower support costs through more effective automation
- Better customer satisfaction through accurate, helpful responses
Summary
AI hallucination doesn't have to be the enemy of your Salesforce AI initiatives. By implementing a three-layer defense strategy – model configuration, prompt grounding, and content optimization – combined with systematic user feedback collection, you can build AI systems that users actually trust.
The key is starting simple with temperature adjustments and grounding rules, which solve 80-90% of hallucination issues immediately. Then build up your content optimization and feedback systems for continuous improvement.
Remember: the goal isn't to make your AI omniscient. It's to make your AI honest about what it knows and doesn't know.
Ready to build trustworthy AI that never makes things up? Book a demo to see GPTfy's anti-hallucination features in action.
Want to learn more?
View the Datasheet
Get the full product overview with architecture details, security specs, and pricing — with a built-in print option.
Watch a 2-Minute Demo
See GPTfy in action inside Salesforce - from prompt configuration to AI-generated output in real time.
Ready to see it with your data? Book a Demo
Explore GPTfy